

Strategies for Data Imbalance in Fraud Classifiers
For years, fraudsters would file claims and collect money from overstated or completely made up injuries and disabilities.


For years, fraudsters would file claims and collect money from overstated or completely made up injuries and disabilities.
Nevertheless, experts predict online insurance fraud to soar to a whopping $32 billion in 2020.
Putting it into perspective, this amount is superior to the profits posted recently by some worldwide household, blue chip companies in 2017, such as Coca-Cola ($2 billions), Warren Buffets Berkshire Hathaway ($24 billions) and JP Morgan Chase ($23.5 billions).
In addition to the implementation of chip card technology, companies have been investing massive amounts in other technologies for detecting fraudulent transactions.
Would Machine Learning & AI constitute great allies in this battle?
Classification Problems

In Machine Learning, problems like fraud detection are usually framed as classification problems predicting a discrete class label output given a data observation. Examples of classification problems that can be thought of are Spam Detectors, Recommender Systems and Loan Default Prediction.
Talking about the payment fraud detection, the classification problem involves creating models that have enough intelligence in order to properly classify transactions as either legit or fraudulent, based on transaction details such as amount, merchant, location, time and others.
Financial fraud still amounts for considerable amounts of money. Hackers and crooks around the world are always looking into new ways of committing financial fraud at each minute. Relying exclusively on rule-based, conventionally programmed systems for detecting financial fraud would not provide the appropriate time-to-market. This is where Machine Learning shines as a unique solution for this type of problem.
The main challenge when it comes to modeling fraud detection as a classification problem comes from the fact that in real world data, the majority of transactions is not fraudulent. Investment in technology for fraud detection has increased over the years so this shouldn’t be a surprise, but this brings us a problem: imbalanced data.
Imbalanced Data

Imagine that you are a teacher. The school director gives you the task of generating a report with predictions for each of the students final year result: pass or fail. You’re supposed to come up with these predictions by analyzing student data from previous years: grades, absences, engagement together with the final result, the target variable which could be either pass o fail. You must submit your report in some minutes.
The problem here is that you are a very good teacher. As a result, almost none of your past students has failed your classes. Let’s say that 99% of your students have passed final year exams.
What would you do?
The most fast, straightforward way to proceed in this case would be predicting that 100% of all your students would pass. Accuracy in this case would be 99% when simulating past years. Not bad, right?
https://towardsdatascience.com/media/f1c972d20aa4fea4df8f0ee8e32a96be?postId=a03f8815cce9
This happens when we have imbalance.
Would this model be correct and fault proof regardless of characteristics from all your future student populations?
Certainly not. Perhaps you wouldn’t even need a teacher to do these predictions, as anyone could simply try guessing that the whole class would pass based on data from previous years, and still achieve a good accuracy rate. Bottomline is that this prediction would have no value. And one of the most important missions of a Data Scientist is creating business value out of data.

We’ll take a look into a practical case of fraud detection and learn how to overcome the issue with imbalanced data.
Our Data

Our dataset contains transactions made by users of european cardholders. This dataset presents transactions that occurred in two days, where we have 492 frauds out of 284,807 transactions. The dataset is highly imbalanced, with the positive class (frauds) accounting for 0.172% of all transactions.

It is important to note that due to confidentiality reasons, the data was anonymized? variable names were renamed to V1, V2, V3 until V28. Moreover, most of it was scaled, except for the Amount and Class variables, the latter being our binary, target variable.
It is always good to do some EDA Exploratory Data Analysis before getting our hands dirty with our prediction models and analysis. But since this is an unique case where most variables add no context, as they have been anonymized, we’ll skip directly to our problem: dealing with imbalanced data.

There are many ways of dealing with imbalanced data. We will focus in the following approaches:
- Oversampling? SMOTE
- Undersampling? RandomUnderSampler
- Combined Class Methods? SMOTE + ENN
Approach 1: Oversampling

One popular way to deal with imbalanced data is by oversampling. To oversample means to artificially create observations in our data set belonging to the class that is under represented in our data.
One common technique is SMOTE Synthetic Minority Over-sampling Technique. At a high level, SMOTE creates synthetic observations of the minority class (in this case, fraudulent transactions). At a lower level, SMOTE performs the following steps:
- Finding the k-nearest-neighbors for minority class observations (finding similar observations)
- Randomly choosing one of the k-nearest-neighbors and using it to create a similar, but randomly tweaked, new observations.
There are many SMOTE implementations out there. In our case, we will leverage the SMOTE class from the imblearn library. The imblearn library is a really useful toolbox for dealing with imbalanced data problems.
To learn more about the SMOTE technique, you can check out this link.
Approach 2: Undersampling

Undersampling works by sampling the dominant class to reduce the number of samples. One simple way of undersampling is randomly selecting a handful of samples from the class that is overrepresented.
The RandomUnderSampler class from the imblearn library is a fast and easy way to balance the data by randomly selecting a subset of data for the targeted classes. It works by performing k-means clustering on the majority class and removing data points from high-density centroids.
Approach 3: Combined Class Methods

SMOTE can generate noisy samples by interpolating new points between marginal outliers and inliers. This issue can be solved by cleaning the resulted space obtained after over-sampling.
In this regard, we will use SMOTE together with edited nearest-neighbours(ENN). Here, ENN is used as the cleaning method after SMOTE over-sampling to obtain a cleaner space. This is something that is easily achievable by using learn SMOTEENN class.
Initial Results
Our model uses a Random Forests Classifier in order to predict fraudulent transactions. Without doing anything to tackle the issue of imbalanced data, our model was able to achieve 100% precision for the negative class label.
This was expected since we were dealing with imbalanced data, so for the model it was easy to notice that predicting everything as negative class will reduce the error.

We have some good results for precision, considering both classes. However, recall is not as good as precision for the positive class (fraud).
Let’s add one more dimension to our analysis and check the Area Under the Receiver-Operating Characteristic (AUROC) metric. Intuitively, AUROC represents the likelihood of your model distinguishing observations from two classes. In other words, if you randomly select one observation from each class, what is the probability that your model will be able to rank them correctly?

Our AUROC score is already pretty decent. Were we able to improve it even further?
So, Have We Won?

After using oversampling, undersampling and combined class approaches for dealing with imbalanced data, we got the following results.
- SMOTE

By using SMOTE in order to oversample our data, we got some mixed results. We were able to improve our recall for the positive class by 5% we reduced false positives. However, that came with a price: our precision is now 5% worse than before. It is common to have a precision recall trade-off in Machine Learning. In this specific case, it is important to analyze how would this impact us financially.

In one side, we have the financial amount that would be lost due to the increase in false negatives, thus decreased fraud detection precision. On the other, we could potentially be losing clients due to wrongfully classifying transactions as fraud, as well as increasing operational costs for cancelling credit, printing new ones and posting them to the clients.
In terms of AUROC, we got a slightly better score:

- RandomUnderSampler
Undersampling proved to be a bad approach for this problem. While our recall score has improved, precision for the positive class has almost vanished.

The results above show us that it wouldn’t be a good strategy to use undersampling for dealing with our imbalanced data problem.
- SMOTE + ENN

SMOTE + ENN proved to be the best approach in our scenario. While precision was penalized by 5% like with SMOTE, our recall score was increased by 7%.
As for the AUROC metric, the result was also better:

Recap
In this post, I showed three different approaches to deal with imbalanced data all of the leveraging the imblearn library:
- Oversampling (using SMOTE)
- Undersampling (using RandomUnderSampler)
- Combined Approach (using SMOTE+ENN)
Key Takeaways
- Imbalanced data can be a serious problem for building predictive models, as it can affect our prediction capabilities and mask the fact that our model is not doing so good
- Imblearn provides some great functionality for dealing with imbalanced data
- Depending on your data, SMOTE, RandomUnderSampler or SMOTE + ENN techniques could be used. Each approach is different and it is really the matter of understanding which of them makes more sense for your situation.
- It is important considering the trade-off between precision and recall and deciding accordingly which of them to prioritize when possible, considering possible business outcomes.
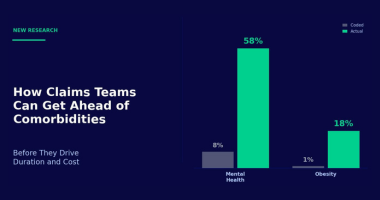





AI powered Claims Guidance.


